从偏差到公平:Uplift 建模中的去偏技术

梁杰 马上消费金融股份有限公司 高级算法工程师
从偏差到公平:Uplift 建模中的去偏技术
导读
在大模型时代数据科学的变与不变的活动中,梁杰老师系统探讨了因果推断中消除数据偏差的核心挑战与技术路径。文章围绕以下几点展开:
1. Uplift 建模基础与挑战
2. 去偏技术核心方法
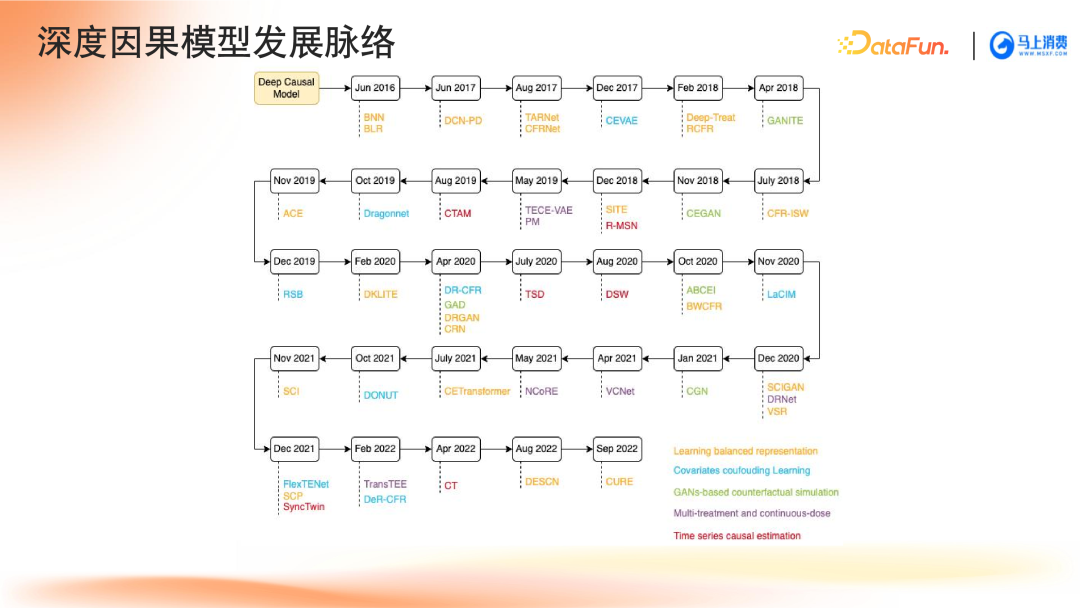
3. 深度因果模型发展脉络
01 Uplift 建模的基础与挑战
1. Uplift 建模的核心目标
Uplift 建模主要用于在预算或资源有限的场景下,最大化业务目标与成本(ROI)效率。其核心是准确评估干预(如营销策略、提额)对个体的因果效应。
2. 随机无偏数据的重要性
- 随机无偏数据:通过随机控制实验(RCT)获取,当数据量足够大时,实验组与控制组的数据分布基本一致。
- Uplift 应用效应:在同一周期内,使用随机无偏数据观测对照实验结果,评估干预应用效应。
- 局限性:实际业务中因成本限制等因素难以获取足够无偏数据,同时线上干扰因素引入混淆偏差。
3. 混淆偏差与归纳偏差
- 混淆偏差:由未被控制的干扰变量导致干预组与对照组数据分布差异。
- 归纳偏差:由于建模方法的局限性导致对因果效应的误判。
02 去偏技术核心方法
1. 去偏方法概述
(1)混淆偏差的消除方向
- 核心问题:在数据分布不平衡时,需通过方法消除混淆变量对干预效应评估的干扰。
- 方法分类:重加权、样本匹配、深度模型等。
| 方法类型 | 核心思想 |
| 重加权 | 通过权重调整样本重要性 |
| 样本匹配 | 找到两组间相似样本进行配对 |
| 深度模型 - 表示学习 | 区分干预和不干预,进行特征学习。 |
| 深度模型 - 协变量混淆学习 | 因果表征解耦、重加权、编解码器重构等 |
| 深度模型 - 对抗生成网络 | 生成反事实输出结果,用于平衡表示空间分布 |
| 深度模型 - 时间序列因果预估 | 一个持续的因果预估 |
| 深度模型 - 多 treatment 和连续因果问题 | 多 treatment 和连续 treatment 的因果估计 |
(2)倾向得分(PS)充分性定理
- 场景:在重加权和样本匹配的场景下
- 定义:个体在给定混淆变量 X 下接受干预的条件概率。
- 理论基础:倾向性得分充分性定理表明,当给定倾向得分时,干预分配与潜在结果独立,可替代原始的高维协变量 X 简化分析,就可以简化因果效应的工具。
- 应用条件:强可忽略性、正值假设
- 局限性:
- 高度依赖倾向性得分模型的正确性
- 依赖所有混淆变量被观测,且 PS 需在 (0,1) 范围内,无法处理未观测混淆变量。
2. 去偏方法详解
(1)样本重加权方法
方法思路:通过样本加权的方式,完成干预组和对照组的数据对齐。给予在普通情况下倾向性更低的样本更高的权重;倾向性更高的样本则给予更低的权重,重建一个平衡的样本集,使样本集特征更好代表无偏人群。
经典方法 - 逆倾向概率加权(IPW)- 原理:用混淆变量实现一个倾向性得分模型,针对每个样本计算得到权重,评估整个实验平均的因果效应。
- 局限性:倾向性得分(PS)估计的误差会直接影响结果。
- 风险:极端 PS 值可能导致结果偏差,需要通过阈值过滤异常值额外进行处理。
(2)匹配方法
① 经典方法 - 样本匹配方法 (PSM)原理:对于每一个观测样本,找和其背景变量相似,不在同一个 treatment 组下的样本作对比,计算因果效应。
实现步骤:- 距离度量:评估干预组和非子干预组样本之间的一个相似性,如欧氏距离、卡方距离,评估样本相似性。
因果推断中的混淆偏差去偏方法全解析
1. 样本匹配法
- 核心思想:通过构造对照组和实验组的平衡数据集,消除混淆变量影响。
- 常用匹配方法:NNM(最近邻匹配)、caliper(卡尺匹配)、分层匹配、kernel(核函数匹配)等。
2. 倾向性得分匹配(PSM)的关键步骤
- 选择协变量Xi:尽可能涵盖影响结果和干预的所有相关变量。
- 估计倾向得分:采用logit或probit模型预测个体接受干预的概率。
- 样本匹配:根据得分匹配处理组与对照组以达到协变量平衡。
- 平行假设检验:验证协变量在匹配后的组间均值是否接近。
- 估计处理效应:基于匹配后样本,分析两组差异以评估干预影响。
3. 不同匹配方法对比
- 最近邻匹配(NNM):找到最相似的观测样本进行配对。适用于小样本,但若分布差异大可能无法有效匹配。
- 卡尺匹配(Caliper Matching):设置匹配距离阈值(如PS差<0.05),确保仅在容许范围内匹配。
- 核函数匹配(Kernel Matching):通过降维实现多维变量匹配,支持一对一或多对一匹配策略:
- 一对一:减少偏差,但匹配样本量有限。
- 一对多:增加样本量的同时引入更多偏差。

重加权(ReWeighting)和倾向得分匹配(PSM)为传统因果推断方法,适用于政策评估或策略优化场景。当业务规则限制干预手段时,可通过对数据去偏,识别最优干预方式并推动上线。
4. 深度学习驱动的去偏技术
- 目标:通过特征提取与表征学习,隔离混淆变量影响,提升因果效应估计准确性。
- 代表方法:
- Balance表示学习:确保干预组和对照组在表征空间上的一致性。
- TarNet:基于T-Learner结构,共享底层表征网络,分别建模干预与非干预结果。
- CFRNet:在TarNet基础上引入IPM损失函数,量化分布差异,提升空间平衡性。
- Weighted CFRNet:进一步加入逆倾向概率加权策略,优化分布修正。
- DragonNet:端到端联合训练倾向评分与潜在结果模型,主动纠偏混淆变量。
- 因果表征解耦:分离表征空间中与因果效应无关的信息,降低混淆偏倚。
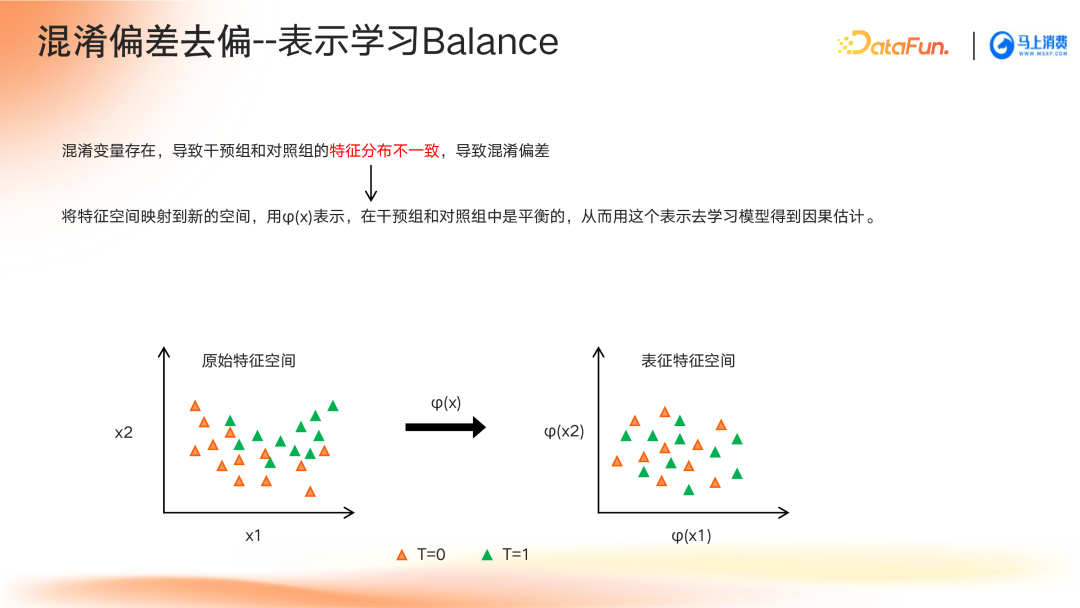
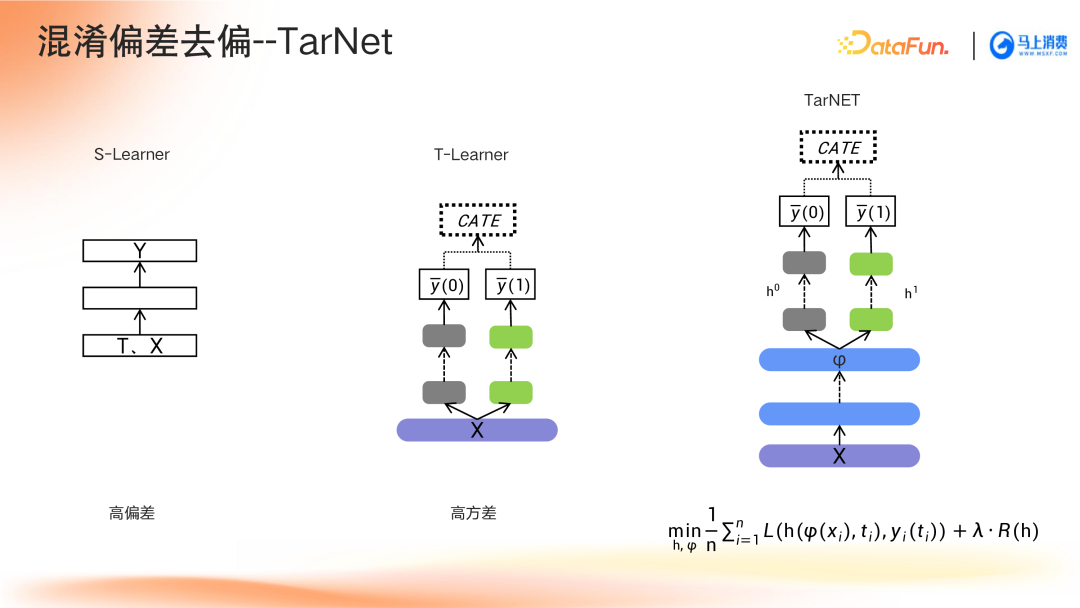
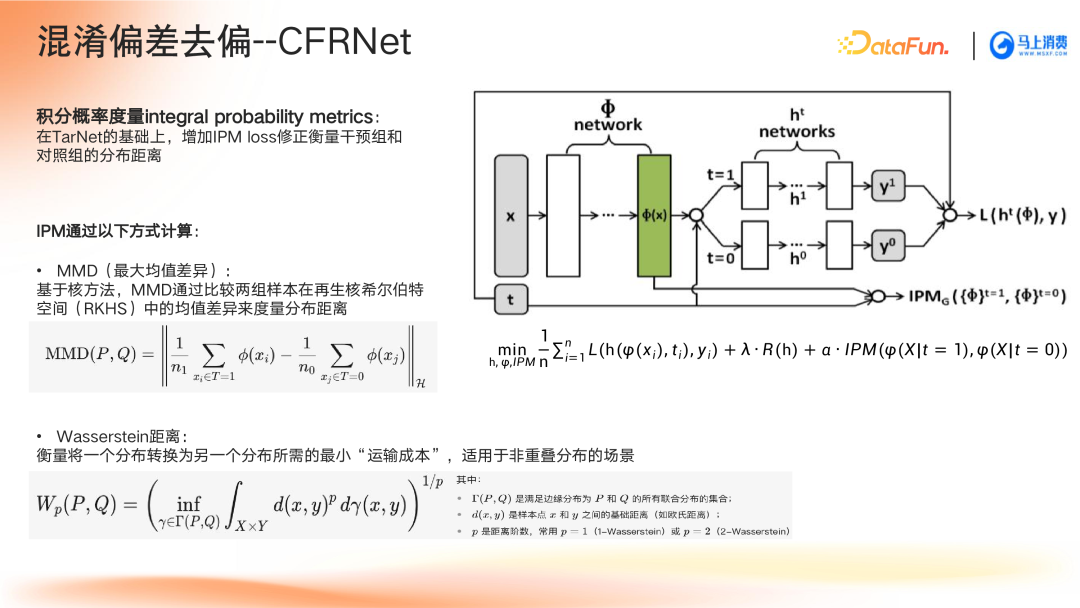
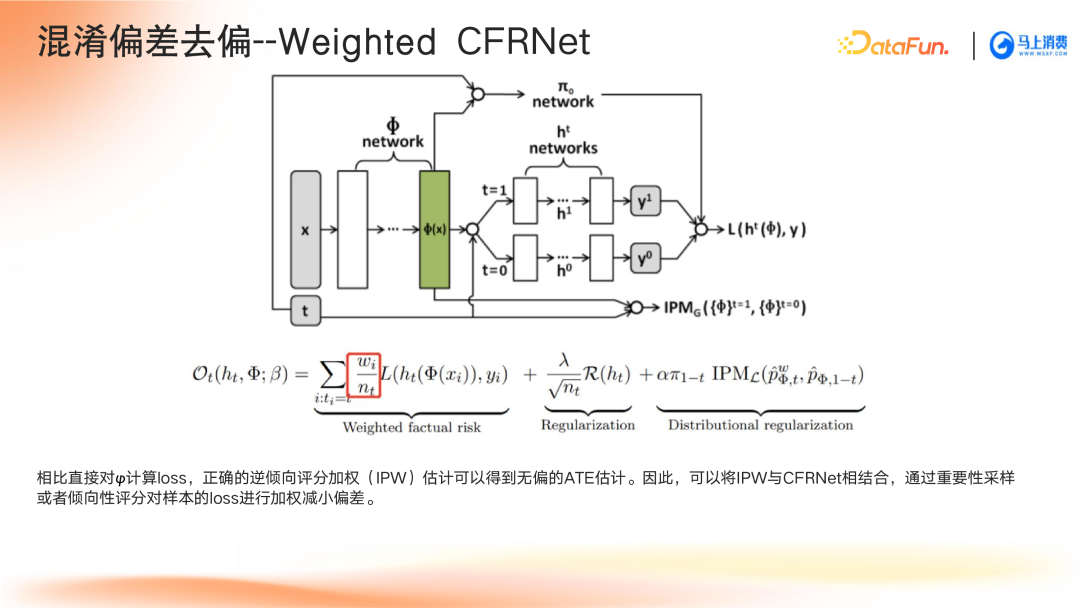
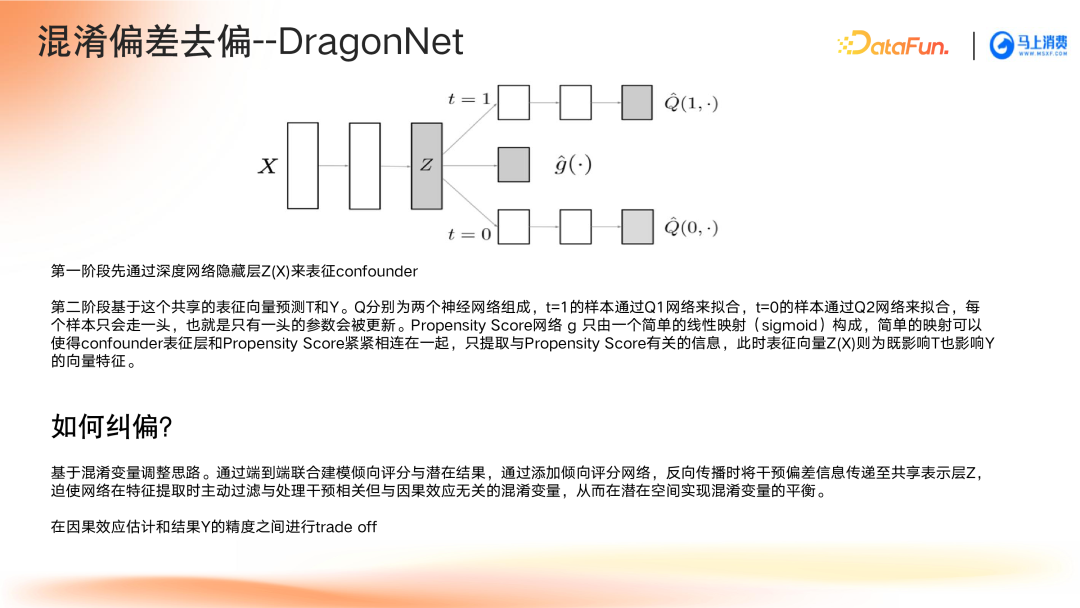
深度因果模型中的特征分类与去偏方法解析
特征分类与Uplift建模的优化路径
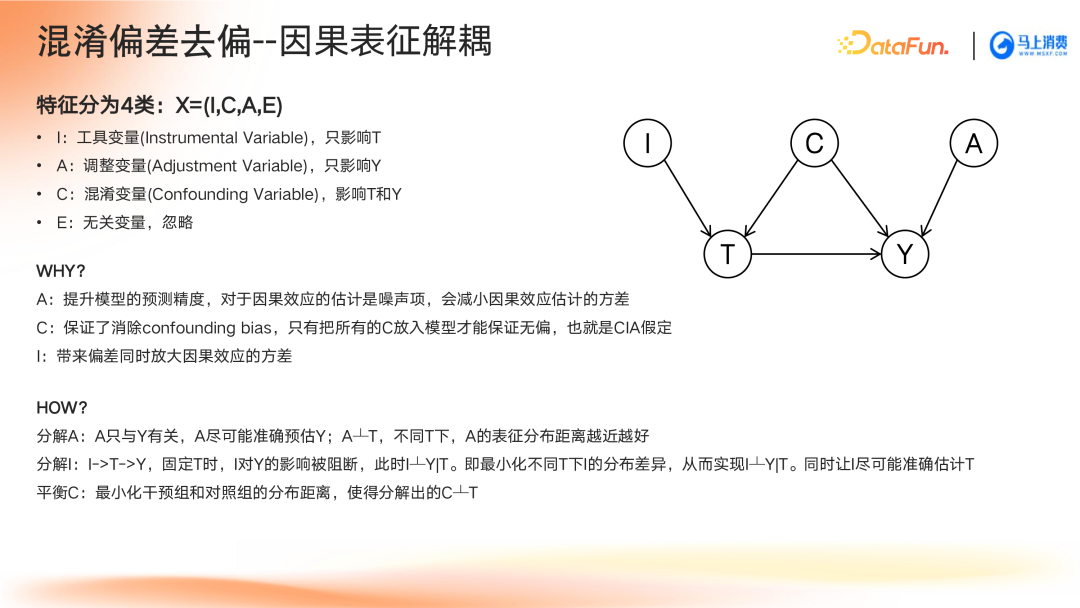
在Uplift建模场景中,特征可被划分为以下四类:
- 工具变量(Instrumental Variable, I):仅影响干预变量T。
- 调整变量(Adjustment Variable, A):仅影响预测结果变量Y。
- 混淆变量(Confounding Variable, C):同时影响干预变量T和结果变量Y。
- 无关变量(E):对模型无意义,可忽略。
去偏步骤主要涉及以下几个方面:
- 调整变量分解:提取与结果变量Y相关的独立变量,并确保不同干预下的表征保持一致性。
- 工具变量分解:工具变量通过干预T影响结果Y。当干预固定时,其影响路径消失,需最小化干预引发的分布差异。
- 混淆变量平衡:在给定干预条件下,使工具变量与结果变量相互独立,并最小化实验组与对照组之间的分布距离,实现变量表征平衡。
⑦ 混淆偏差去偏方法—DeR-CFR
- 调整变量网络设计:构建网络gA拟合结果变量Y,同时保证A(X)在不同干预条件下的分布尽可能接近。
- 混淆变量网络平衡:设计损失函数,确保混淆变量的表征与干预T保持独立,平衡实验组和对照组之间C(X)的分布。
- 工具变量分离策略:利用倾向评分模型gT最大化I(X)对T的拟合能力,同时保证在特定干预下,工具变量与结果变量无关,并最小化其分布差异。

深度因果模型的发展脉络与未来方向
当前五种主流方法已在研究框架中标注,并展示了后续发展的可能方向。未来更多模型将被用于解决复杂的实际业务问题,特别是在信贷、推荐系统、在线营销等领域具备广泛应用潜力。
展开查看全文
文章来源:【DataFunSummit】公众号,原文《从偏差到公平:Uplift 建模中的去偏技术》,大数AI优化
DataFunSummit
DataFun社区旗下账号,专注于分享大数据、人工智能领域行业峰会信息和嘉宾演讲内容,定期提供资料合集下载。